Sparse accumulation
This package contains significantly optimized CPU and GPU PyTorch extensions for the operation we call sparse accumulation. This operation takes two input arrays - X_1 and X_2, and produces an output one, given the transformation rule defined by one-dimensional arrays m_1, m_2, mu, and C. The functional form can be best explained by the following pseudocode:
output = torch.zeros([..., output_size])
for index in range(m_1.shape[0]):
output[..., mu[index]] += X_1[..., m_1[index]] * X_2[..., m_2[index]] * C[index]
This operation is required for SO(3) equivariant neural networks and other machine learning models. The fundamental building block of such methods is the so-called Clebsch-Gordan iteration given by:
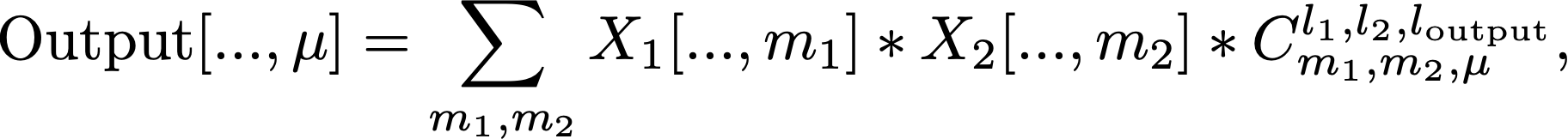
where \(C_{m_1, m_2, \mu}^{l_1, l_2, l_{output}}\) are the Clebsch-Gordan coefficients. These coefficients are sparse, particularly for the complex-valued version the sparsity pattern is that the only non-zero values are for \(m_1 + m_2 = \mu\). For the real-valued version, the sparsity pattern is more complicated, but still, only a small ratio of the entries are non-zeros. Thus, it makes sense to store only non-zero values in a one-dimensional array. In this case, one needs to provide additional arrays with indices providing the information about the corresponding \(m_1\), \(m_2\) and \(\mu\). With such data organization, the CG iteration falls to the defined above sparse accumulation operation.
Our benchmarks show that our custom PyTorch extension while being memory efficient, is significantly faster compared to all alternative implementations we were able to come up with, including dense matrix multiplication (with a lot of zeros inside due to sparsity of CG coefficients), sparse matrix multiplication using PyTorch sparse engine and the one relying on PyTorch index_add.
[todo] benchmark against e3nn
All the benchmarks measurements and reference implementations details can be found in the [todo: structure results into the table] benchmarks section.
Installation
python3 -m pip install .
Tests
gpu tests:
python3 -m pytest tests/test_cpp_jit_cuda.py -vrA
cpu tests:
python3 -m pytest tests/test_cpp_contiguous.py
Benchmarks
Reference Guide